


Generative AI không chỉ giới hạn trong việc xử lý văn bản mà còn đang phát triển mạnh mẽ trong sáng tạo hình ảnh. Bài viết này của A Website sẽ cùng bạn khám phá cách mà các công nghệ như Dall-E2 hay Midjourney tạo ra những tác phẩm độc đáo, thu hút sự chú ý từ cộng đồng AI và giới thiết kế.
Vậy làm thế nào AI tạo sinh có thể sáng tạo ra tranh ảnh? Đâu là những công nghệ đứng đằng sau mô hình này?
“Bóc tách” một số công nghệ phổ biến nhất, từ đó mang đến cái nhìn tổng quan về cơ chế tạo sinh hình ảnh của AI.

Ảnh Phật Tổ tạo bằng AI với đồ họa sắc nét, bàn tay và các chi tiết thể hiện sự chân thật
Khái niệm AI Tạo sinh hình ảnh?
Các trình tạo hình ảnh bằng AI sử dụng mạng thần kinh nhân tạo được huấn luyện trước để tạo ra các hình ảnh mới dựa trên dữ liệu. Những mô hình này có khả năng tạo ra các hình ảnh độc đáo và chân thực, thường dựa trên thông tin văn bản đầu vào được viết bằng ngôn ngữ tự nhiên. Đặc biệt, chúng có khả năng kết hợp các phong cách, ý tưởng và đặc điểm để tạo ra các tác phẩm hình ảnh mang tính nghệ thuật và phù hợp với ngữ cảnh. Tất cả điều này được thực hiện thông qua Generative AI, một nhánh của trí tuệ nhân tạo tập trung vào việc tạo nội dung mới.
Trong quá trình đào tạo, AI tạo sinh ảnh được truyền đủ dữ liệu hình ảnh và văn bản để học hiểu các đặc điểm và khía cạnh của hình ảnh tương ứng với nội dung mô tả. Kết quả là, chúng có khả năng tạo ra các hình ảnh mới với phong cách và nội dung theo yêu cầu, dựa trên kiến thức đã học được trong quá trình huấn luyện.
Có nhiều kỹ thuật và mô hình trong lĩnh vực này, mỗi một mang lại những tính năng đặc biệt. Ví dụ, neural style transfer cho phép áp dụng phong cách của một hình ảnh lên một hình ảnh khác; Generative Adversarial Networks (GANs) sử dụng cặp mạng thần kinh để huấn luyện và tạo ra hình ảnh mới dựa trên dữ liệu huấn luyện; và các mô hình diffusion sử dụng quá trình mô phỏng sự khuếch tán của các hạt để tạo ra hình ảnh từ nhiễu, dần dần chuyển đổi thành hình ảnh có cấu trúc.
Có nhiều kỹ thuật và mô hình trong lĩnh vực này, mỗi một mang lại những tính năng đặc biệt. Ví dụ, neural style transfer cho phép áp dụng phong cách của một hình ảnh lên một hình ảnh khác; Generative Adversarial Networks (GANs) sử dụng cặp mạng thần kinh để huấn luyện và tạo ra hình ảnh mới dựa trên dữ liệu huấn luyện; và các mô hình diffusion sử dụng quá trình mô phỏng sự khuếch tán của các hạt để tạo ra hình ảnh từ nhiễu, dần dần chuyển đổi thành hình ảnh có cấu trúc.
Công nghệ Hậu Phát triển AI Tạo Hình Ảnh
Xử Lý Ngôn Ngữ Tự Nhiên (NLP)
Trong quá trình tạo hình ảnh bằng trí tuệ nhân tạo, trình tạo hình ảnh AI sử dụng công nghệ Xử Lý Ngôn Ngữ Tự Nhiên (NLP) để hiểu các prompt văn bản. Điều này được thực hiện thông qua một quy trình phức tạp, bắt đầu với việc chuyển đổi dữ liệu văn bản sang ngôn ngữ máy tính, thường dưới dạng các vectơ số hoặc nhúng. Mô hình NLP, như CLIP, là một ví dụ điển hình, được tích hợp vào các trình tạo hình ảnh nổi tiếng như DALL-E.
Quá trình này chuyển đổi văn bản thành các vectơ, biểu diễn ý nghĩa và ngữ cảnh của nó. Mỗi giá trị trên vectơ đại diện cho một thuộc tính cụ thể trong văn bản. Ví dụ, từ prompt "quả táo đỏ trên cây", mô hình NLP sẽ mã hóa các yếu tố như "đỏ", "quả táo", và "cây", cũng như mối quan hệ giữa chúng.
Sau khi có được biểu diễn số từ văn bản, trình tạo hình ảnh sử dụng các thông tin này để tạo ra hình ảnh tương ứng. Các bản đồ này hoạt động như hướng dẫn, giúp AI khám phá các biến thể hình ảnh phù hợp nhất với ngữ cảnh được mô tả. Ví dụ, trong trường hợp "quả táo đỏ trên cây", trình tạo hình ảnh sẽ tạo ra một hình ảnh với quả táo đỏ được đặt trên một cây, thay vì ở vị trí khác.
Qua quá trình chuyển đổi thông minh từ văn bản sang hình ảnh, trình tạo hình ảnh AI có khả năng diễn giải và tái hiện trực quan các yêu cầu văn bản một cách sáng tạo và độc đáo, mang lại những kết quả ấn tượng.
Generative Adversarial Networks (GAN)
Trong thế giới của trí tuệ nhân tạo, Generative Adversarial Networks (GAN) nổi lên như một loại thuật toán học máy tinh vi khai thác sức mạnh đồng thời của hai mạng thần kinh, gồm bộ sinh (generator) và bộ phân biệt (discriminator). Thuật ngữ "ngược nhau" tại đây không chỉ đơn thuần là mô tả mối quan hệ, mà còn thể hiện sự đối đầu, mỗi mạng hoạt động với mục tiêu ngược lại của mạng kia.
Kiến Trúc GAN
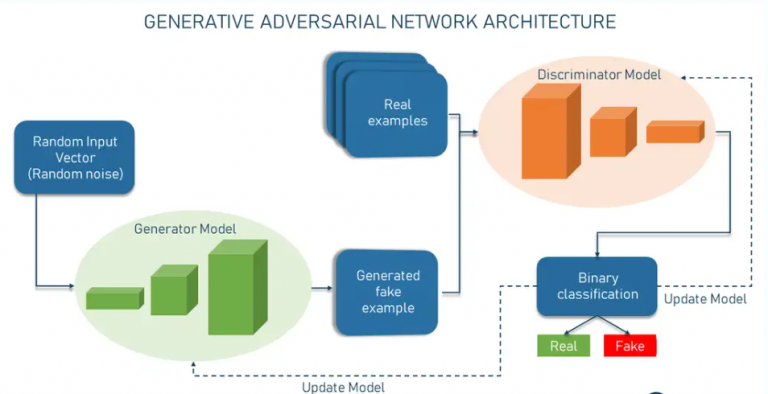
Kiến trúc GAN - Cơ chế hoạt động của GAN
Generative Adversarial Networks (GAN) được cấu thành từ hai thành phần chính, được biết đến là các mô hình phụ:
Bộ Tạo Sinh (Generator): Nhiệm vụ của Generator là tạo ra các mẫu giả. Nó sử dụng một vectơ đầu vào ngẫu nhiên, tức là một tập hợp các giá trị được chọn một cách ngẫu nhiên, và từ thông tin này, nó tạo ra dữ liệu giả mạo.
Bộ Phân Loại (Discriminator): Bộ Discriminator hoạt động như một bộ phân loại nhị phân. Nó nhận một mẫu làm đầu vào và xác định liệu mẫu đó có phải là thật hay được tạo ra bởi Generator.
Sự đối nghịch cơ bản của GAN được lấy cảm hứng từ lý thuyết trò chơi. Generator cố gắng tạo ra các mẫu giả mà Discriminator không thể phân biệt được với dữ liệu thực. Trong khi đó, Discriminator cố gắng phân loại đúng giữa các mẫu thật và giả. Quá trình này đảm bảo rằng cả hai mạng liên tục học hỏi và cải thiện qua thời gian.
Một quá trình GAN được coi là thành công khi Generator có thể tạo ra các hình ảnh giả mà không chỉ đánh lừa được Discriminator mà còn khiến con người khó có thể phân biệt được giữa hình ảnh thực và giả.
Mô Hình Diffusion
Mô Hình Diffusion là một trong những loại mô hình tạo sinh tiên tiến trong lĩnh vực học máy, có khả năng tạo ra dữ liệu mới như hình ảnh hoặc âm thanh bằng cách mô phỏng dữ liệu đã được huấn luyện. Với phương pháp này, mô hình dần dần thêm nhiễu vào dữ liệu và sau đó học cách loại bỏ nhiễu để tái tạo lại dữ liệu gốc.

Diffusion Models chuyển đổi qua lại giữa dữ liệu và nhiễu
Quy trình này bao gồm các bước sau:
Lan Truyền Xuôi (Forward Diffusion): Mô hình bắt đầu với một phần dữ liệu gốc như hình ảnh và dần dần thêm nhiễu ngẫu nhiên qua một chuỗi các bước. Sử dụng Markov chain, mỗi bước dữ liệu thay đổi dựa trên trạng thái trước đó của nó. Nhiễu được thêm vào thường là nhiễu Gaussian, một loại nhiễu ngẫu nhiên phổ biến.
Huấn Luyện (Training): Mô hình học cách ước tính sự khác biệt giữa dữ liệu gốc và dữ liệu đã được thêm nhiễu ở mỗi bước.
Lan Truyền Ngược (Reverse Diffusion): Sau khi được huấn luyện, mô hình cố gắng loại bỏ nhiễu từ dữ liệu đã được thêm vào để khôi phục lại dữ liệu gốc ban đầu.
Tạo Dữ Liệu Mới: Cuối cùng, mô hình sử dụng những gì đã học được trong quá trình lan truyền ngược để tạo ra dữ liệu mới. Ngoài ra, có thể sử dụng prompt bằng văn bản để hướng dẫn mô hình tạo ra các hình ảnh phù hợp.
Neural Style Transfer (NST)
![]()
Diffusion Models chuyển đổi qua lại giữa dữ liệu và nhiễu
Neural Style Transfer (NST) là một ứng dụng tiên tiến của học sâu, kết hợp nội dung từ một hình ảnh với phong cách từ một hình ảnh khác để tạo ra một hình ảnh hoàn toàn mới. Ở mức độ cao, NST sử dụng các mạng thần kinh đã được đào tạo trước để phân tích hình ảnh, cùng với một số phương pháp khác để chuyển đổi phong cách từ một hình ảnh và áp dụng cho hình ảnh khác. Kết quả là hình ảnh mới chứa những đặc điểm mong muốn.
Quá trình NST bao gồm ba hình ảnh cốt lõi:
1. Hình ảnh nội dung: Hình ảnh này chứa nội dung mà bạn muốn giữ lại.
2. Hình ảnh phong cách: Đây là hình ảnh chứa phong cách bạn muốn áp dụng.
3. Hình ảnh mới được tạo ra: Hình ảnh này là kết hợp giữa nội dung và phong cách từ hai hình ảnh trên.
Về cơ chế của NST:
Content loss: Đo lường sự khác biệt về nội dung giữa hình ảnh được tạo và hình ảnh gốc. NST sử dụng nhiều lớp mạng thần kinh để nắm bắt các yếu tố quan trọng trong hình ảnh và đảm bảo chúng xuất hiện trong hình ảnh mới.
Style loss: Đo lường sự khác biệt về phong cách, chẳng hạn như các mẫu và họa tiết, giữa hình ảnh được tạo và hình ảnh gốc. NST cố gắng phù hợp các họa tiết và mẫu trên các lớp của hình ảnh mới với hình ảnh gốc.
Total loss: NST kết hợp content loss và style loss thành một chỉ số duy nhất gọi là total loss. Nó cho phép người phát triển điều chỉnh mức độ quan tâm đến nội dung và phong cách trong quá trình tạo hình ảnh mới. Sau đó, thuật toán tối ưu hóa được sử dụng để điều chỉnh các pixel trong hình ảnh mới để giảm thiểu total loss.
Sau quá trình tối ưu hóa, hình ảnh mới được tạo ra sẽ kết hợp nội dung và phong cách từ hai hình ảnh khác nhau.
Các công nghệ như GAN, NST và Diffusion model chỉ là một số ví dụ trong số các kỹ thuật tạo ảnh AI gần đây, thu hút sự chú ý đặc biệt từ cộng đồng nghiên cứu. Các nhà nghiên cứu vẫn tiếp tục khám phá và phát triển những kỹ thuật phức tạp mới, mở ra tiềm năng vô hạn của trí tuệ nhân tạo trong việc tạo ra hình ảnh.

